1 - Introducción a las bases de datos
Declaración de intenciones
Vamos a intentar conocer como funciona MySql.
Para sacarle el máximo partido a estos apuntes tendréis que tener acceso al phpMyAdmin, la interfaz gráfica de vuestra base de datos. Experimentar es la única manera de aprender. Lo mejor sería que para hacer las prácticas os instaláseis una nueva base de datos y la destináseis única y exclusivamente para hacer estos ejercicios.
Vamos a intentar conocer como funciona MySql.
Para sacarle el máximo partido a estos apuntes tendréis que tener acceso al phpMyAdmin, la interfaz gráfica de vuestra base de datos. Experimentar es la única manera de aprender. Lo mejor sería que para hacer las prácticas os instaláseis una nueva base de datos y la destináseis única y exclusivamente para hacer estos ejercicios.
Antes de empezar a hacer experimentos aseguraos que sabéis hacer una copia de seguridad de vuestros datos y, sobretodo, que podéis restaurar esa copia en el servidor que tenéis, luego ya podéis empezar a experimentar con toda seguridad.
Voy a tratar de dar una descripción apoyándome en ejemplos de la vida corriente y en un ejemplo de referencia: las fichas de nuestra particular biblioteca. Con que "veáis" como funciona esa característica o concepto es suficiente. Todo se irá haciendo más familiar conforme avancemos.
Ir comprendiendo poco a poco como funciona ese gestor de bases de datos. Conforme vayamos avanzando y conforme volváis a releer los capítulos, las cosas irán adquiriendo sentido.
Veréis que he intercalado un capítulo dedicado a prácticas en el administrador de MySql. La idea es que afiancemos los conceptos aprendidos viendo como está hecha la base de datos de los foros. Nos dará ocasión también para repasar los conceptos y será el momento de volver a releer aquellas cosas que al principio no quedaron suficientemente claras.
Voy a tratar de dar una descripción apoyándome en ejemplos de la vida corriente y en un ejemplo de referencia: las fichas de nuestra particular biblioteca. Con que "veáis" como funciona esa característica o concepto es suficiente. Todo se irá haciendo más familiar conforme avancemos.
Ir comprendiendo poco a poco como funciona ese gestor de bases de datos. Conforme vayamos avanzando y conforme volváis a releer los capítulos, las cosas irán adquiriendo sentido.
Veréis que he intercalado un capítulo dedicado a prácticas en el administrador de MySql. La idea es que afiancemos los conceptos aprendidos viendo como está hecha la base de datos de los foros. Nos dará ocasión también para repasar los conceptos y será el momento de volver a releer aquellas cosas que al principio no quedaron suficientemente claras.
2 - Tipos de Gestores de Bases de Datos
Un gestor de base de datos o sistema de gestión de base de datos (SGBD o DBMS) es un software que permite introducir, organizar y recuperar la información de las bases de datos; en definitiva, administrarlas. Existen distintos tipos de gestores de bases de datos. El modelo relacional es el utilizado por casi todos los gestores de bases de datos para PC´s. El modelo relacional (SGBDR) es un software que almacena los datos en forma de tablas.
Características Generales de los Sistemas Gestores de B.D.
Aunque hay multitud de aplicaciones para la Gestión de Bases de Datos diferentes en características y precios, podemos encontrar aspectos comunes en todos ellos:
• Aceptan definiciones de esquemas y vistas (definición de diferentes bases de datos).
• Manipulan los datos siguiendo las órdenes de los usuarios.
• Cuidan que se respete la seguridad e integridad de los datos.
• Permiten definir usuarios y las restricciones de acceso para cada uno de ellos.
• Controlan la concurrencia y las operaciones asociadas a la recuperación de los fallos.
Características Generales de los Sistemas Gestores de B.D.
Aunque hay multitud de aplicaciones para la Gestión de Bases de Datos diferentes en características y precios, podemos encontrar aspectos comunes en todos ellos:
• Aceptan definiciones de esquemas y vistas (definición de diferentes bases de datos).
• Manipulan los datos siguiendo las órdenes de los usuarios.
• Cuidan que se respete la seguridad e integridad de los datos.
• Permiten definir usuarios y las restricciones de acceso para cada uno de ellos.
• Controlan la concurrencia y las operaciones asociadas a la recuperación de los fallos.
3 – Elementos
Una base de datos está formada por: los datos: Que deben ser INTEGRADOS, es decir, que en la unión de los archivos que forman el sistema no exista redundancia de datos Veamos el ejemplo de la gestión de los libros de una biblioteca. Seguramente la imagen de abajo os será familiar: Una ficha con datos de un libro, una ficha con datos de un lector y una ficha mostrando el listado de lecturas de un libro, esa ficha que nos entregan junto al libro cuándo nos lo prestan en la biblioteca. Si hacemos un listado con el nombre de los campos que hemos introducido en esas fichas obtendríamos:
//++
++//TítuloAutorEditorialAñoIdiomaLectorFecha pdevoluciónNombreApellidosDomicilioTeléfonoDNINotad que he omitido las referencias : Ref_libro y Ref_lector , son datos particulares de los que hablaremos específicamente más adelante.Cada dato de ese listado_suma , aparece en una ficha junto a otros con los que se relaciona, y ningún dato se repite en el resto de las fichas, por lo tanto los datos están integrados.Hardware: Es el soporte físico que permite almacenar la información de la base de datos. Nosotros por el momento trabajaremos con un solo soporte físico, pero hay que saber que una base de datos puede estar formada por varios sistemas, entonces se llama base de datos distribuidal manejo de este tipo de bases de datos compartidas se complica ya que se necesita comunicación entre los sarios: Hay tres tipos de usuarios.Programadores de aplicaciones: Se encargan de diseñar y programar las aplicaciones necesarias para la utilización de la B.D., realizando las peticiones pertinentes al SGBD.
++//TítuloAutorEditorialAñoIdiomaLectorFecha pdevoluciónNombreApellidosDomicilioTeléfonoDNINotad que he omitido las referencias : Ref_libro y Ref_lector , son datos particulares de los que hablaremos específicamente más adelante.Cada dato de ese listado_suma , aparece en una ficha junto a otros con los que se relaciona, y ningún dato se repite en el resto de las fichas, por lo tanto los datos están integrados.Hardware: Es el soporte físico que permite almacenar la información de la base de datos. Nosotros por el momento trabajaremos con un solo soporte físico, pero hay que saber que una base de datos puede estar formada por varios sistemas, entonces se llama base de datos distribuidal manejo de este tipo de bases de datos compartidas se complica ya que se necesita comunicación entre los sarios: Hay tres tipos de usuarios.Programadores de aplicaciones: Se encargan de diseñar y programar las aplicaciones necesarias para la utilización de la B.D., realizando las peticiones pertinentes al SGBD.
Usuario final: Es la persona que se dedica a trabajar sobre los datos almacenados en la B.D. Hay usuarios finales avanzados que por medio del lenguaje de programación SQL pueden acceder a los datos.Administrador de B.D.:Es el usuario más importante de los tres, ya que es el que se encarga de diseñar y modificar la estructura de la B.D. Dato operativo.Es toda la información que necesitamos para que funcione la base de datos.Las entidades con sus atributos más la conexión que hay entre ellas, a todo esto integrado se le denomina : diseño lógico de la base de datos. Ventajas de las bases de datos frente a los ficheros clásicos. Las principales ventajas de las bases de datos sobre los ficheros clásicos son ://++
++//Control centralizado: lo ostenta el administrador de la B.D.Reducción de redundancias.Eliminación de inconsistencias.Los datos pueden compartirse.Los estándares se mantienen.Mayor seguridad.Mayor facilidad en el chequeo de errores.Equilibran requerimientos opuestos.Independencia de datos.Se dice que una aplicación es dependiente de los datos si es imposible alterar la estructura de almacenamiento o la técnica de acceso sin afectar a la aplicación. En un sistema de bases de datos no es recomendable tener aplicaciones dependientes de los datos por dos razones principales://++
++//a) Cada aplicación puede requerir una vista diferente de los mismos datos.b) El administrador de la B.D. ha de tener libertad para modificar la estructura de almacenamiento o las técnicas de acceso (o las dos cosas) para adaptarla al cambio de los requerimientos sin tener que modificar las aplicaciones ya existentes.Por ejemplo, podemos tres aplicaciones funcionando con la misma base de datos://++
++//.-Un portal temático, por ejemplo de literatura..-Un zona de usuarios avanzados , por ejemplo escritores que publican allí obras..-Unos foros, en dónde escritores y lectores en general comparten opiniones. Cada aplicación extraerá los datos que necesite de la base de datos común y los mostrará en pantalla según los''//++ requerimientos de cada uno de los sitios, pero además pueden estar diseñadas en diferentes lenguajes, php, asp, java ...Lo ideal es que haya independencia de datos a tres niveles:A nivel del campo almacenado: Es la mínima cantidad de información reconocible con un nombre que se almacena - En nuestro ejemplo un campo seria: "Fecha préstamo"A nivel de registro almacenado: Es un conjunto de campos almacenados relacionados entre sí que cuenta con su propio nombre.- En la ficha de lectura un registro seria : 63 / 09-01-04 / 20-01-04 -A nivel de fichero almacenado: Es el conjunto de todas las ocurrencias almacenadas para un tipo de registro - En nuestro caso un fichero sería: la ficha del libroRegistro lógico = Registro que ve el usuario.Registro físico = Registro tal y como se almacena en la base de datos.
4 - Clave principal o Primary Key
Los datos operativos están formados por los ítems de datos superiores reconocidos por un nombre y estas entidades tienen unos atributos. Las entidades se componen de atributos que son todo aquello que puede tomar un valor en un dominio fijo. Para pasar de una entidad a otra se hace mediante conexiones basadas en atributos compartidos que le van a dar un carácter semántico"Definido así puede dar un poco de miedo, pero en realidad es algo muy simple. Veamos otra vez nuestro ejemplo.

"Los miserables" es uno más de los títulos de los libros que tenemos en nuestra biblioteca, denominamos a ese tipo de atributo ( que tiene unas características determinadas y son obvias ):" Titulo_libro", y no a otro. Este, junto a varios atributos más del libro: "Autor_libro", "Editorial_libro", "AñoEdicion_libro", "Idioma_libro", nos dan como resultado una: " Ficha del libro" (registro)
"Pedro" es uno más de los nombre de los lectores que tenemos en nuestra biblioteca, denominamos a este atributo ( que tiene unas características determinadas y son obvias):" Nombre_lector", y no a otro. Este, junto a varios atributos más de ese lector : "Apellidos_lector", "Domicilio_lector", "Telefono_lector", "DNI_lector", nos dan como resultado una: "Ficha del lector" (registro)
La entidad libros está formada por tantos registros como libros tengamos en la biblioteca.
La entidad lectores está formada por tantos registros como lectores tengamos registrados en nuestra biblioteca
La entidad "libros" y la entidad "lectores" se conectan a otra entidad "prestamos" por medio de unos atributos comunes que identifican inequívocamente a cada uno de sus registros, son: Ref_libro y Ref_lector
"Pedro" es uno más de los nombre de los lectores que tenemos en nuestra biblioteca, denominamos a este atributo ( que tiene unas características determinadas y son obvias):" Nombre_lector", y no a otro. Este, junto a varios atributos más de ese lector : "Apellidos_lector", "Domicilio_lector", "Telefono_lector", "DNI_lector", nos dan como resultado una: "Ficha del lector" (registro)
La entidad libros está formada por tantos registros como libros tengamos en la biblioteca.
La entidad lectores está formada por tantos registros como lectores tengamos registrados en nuestra biblioteca
La entidad "libros" y la entidad "lectores" se conectan a otra entidad "prestamos" por medio de unos atributos comunes que identifican inequívocamente a cada uno de sus registros, son: Ref_libro y Ref_lector
¿Cómo se conectan o relacionan las entidades?
Veamos dos entidades completamente diferentes : libros y prestamos
La ficha del libro es un registro formado por todos los atributos del libro y nos define las características de ese libro: su autor, el idioma en que está escrito, el título ... todos estos datos son esenciales al libro porque el conjunto de todos ellos define ese libro en particular. Si variásemos una sola característica dejaría de ser ese libro para pasar a convertirse en otro.
Ejemplo:
Título: El Romancero
Autor: anónimo
Recopilación de romances que en su momento se transmitían de forma oral
Título: El Romancero gitano
Autor: García Lorca
Otro libro completamente diferente, aunque sea un romancero
La ficha de lectura nos indica quién y cuándo ha leído ese libro. Que el libro lo haya leído Pedro o Juan en Enero, Febrero o Marzo, que lo tengan en su casa o que esté en la biblioteca, no altera en absoluto lo esencial del libro, no deja de ser ese libro para convertirse en otro. El total de las lecturas anotadas para todos los libros va formando una nueva entidad, una entidad que no es material, la transformamos en material cuando creamos el listado: prestamos. El listado dónde hemos registrado los lectores y las fechas en las que la biblioteca les ha prestado el libro.
Para saber que una determinada ficha de lectura se refiere a un determinado libro, tenemos que tener, tanto en la ficha del libro como en la ficha de lectura, un atributo que nos indique sin lugar a dudas, sin error posible, que se pertenecen. Este atributo es Ref_libro
¿os acordáis en el colegio? ¿no firmábamos con nuestro nombre en nuestro diccionario para saber que era nuestro y diferenciarlo del diccionario del resto de los alumnos? Nuestra firma escrita en el diccionario nos relacionaba inequívocamente con ese diccionario.
¿Cuál será el atributo inequívoco de un coche? ¿Cuál será ese identificador, por el que la Dirección General de Tráfico sabrá cuál es nuestro coche y nos pondrá una multa por saltarnos un stop en la autopista, sin confundirlo con los miles de coches que tienen el mismo color o son de la misma marca?
Si pensáis un poco en los tres últimos ejemplos, os daréis cuenta que el hombre lleva manejando bases de datos y clasificando desde la época de Adán y ha buscado referencias inequívocas e identificadores únicos siempre. Ejemplos actuales de atributos inequívocos son: la matrícula de un coche, el número de pasaporte, el del documento nacional de identidad, el número de teléfono, el número de registro de la propiedad, el número de identificación fiscal, número de serie de los billetes, número de seguro ... todos ellos tienen algo en común, identifican inequívocamente a una persona o cosa entre un conjunto de personas o cosas de características semejantes. (coches, españoles, teléfonos, fincas, contribuyentes, billetes...)
En una base de datos computerizada, los identificadores únicos los creamos nosotros y los llamamos Clave principal
Características de la Clave principal
La clave principal debe ser inequívoca y para cada nuevo registro de datos se obtiene inmediatamente el correspondiente valor que no puede quedarse vacío. Por lo tanto:
Como este atributo siempre debe tener un valor, sea cuál sea, lo definiremos como NOT NULL .
Como se tiene que incrementar en cada nueva ocurrencia y tiene que ser imposible modificarlo, lo definiremos como AUTO_INCREMENT Este atributo puede estar expresamente definido para que sea invisible al usuario corriente, pero siempre será numérico, se generará automáticamente en cada ocurrencia, y aumentará en uno su valor en cada una de ellas.
La clave principal podría muy bien estar definida en un campo INTEGER
Más fácil : el primero tendrá el valor de 1, el segundo de 2, el tercero de 3 , y así, cada vez que recojamos una ocurrencia el gestor irá nombrando inequívocamente cada una de ellas, irá nombrando cada registro.

Nuestra tabla libros podría ser muy bien ésta de aquí arriba. Cuándo se produzca una nueva ocurrencia en esta entidad, es decir, cuándo tengamos que dar de alta un nuevo libro creando un nuevo registro con los datos oportunos, el sistema gestor de nuestra base de datos creará automáticamente un nuevo valor en el campo Ref_libro que será el 531
Existen casos en los que no es suficiente determinar una única clave principal para identificar claramente un registro. Hay ocasiones en las que para realizar esa identificación precisa e inequívoca necesitamos utilizar dos o más atributos. Pensemos en los miembros de una familia.

Supongamos a tres hermanos: Pedro, Julián y Raúl; casados con Isabel y Luisa (hermanas entre ellas) y Adela. Si hiciésemos una tabla con los datos de padres e hijos necesitaríamos identificarlos claramente para no equivocarnos a la hora de introducir los datos pertenecientes a unos u otros.

Echando un primer vistazo vemos que no podríamos declarar único e irrepetible el nombre, tampoco el primer apellido o el segundo... pues en cualquiera de los tres casos tendríamos valores repetidos, si además los hijos son menores, tampoco tenemos un DNI único para cada uno ¿qué hacer entonces?
Podemos elegir varios valores cuya combinación no se repita. En lugar de elegir como clave principal o índice un solo atributo, podemos elegir dos atributos juntos, o tres, de manera que, aunque independientemente esos atributos se repitan en algunos registros, la combinación entre ellos sólo se dé una vez.
No podremos elegir los apellidos ya que la combinación de apellidos se repite dentro de una familia, y en nuestro caso se repite no solo la combinación de apellidos, sino la combinación del nombre, apellido1 y apellido2.
Pero pensemos qué es lo que identifica a un individuo dentro de un grupo familiar .... su nombre propio.
Dentro del grupo de hijos de una misma pareja, el nombre propio de cada hijo es único, ¿conocéis a dos hermanos que tengan el mismo nombre propio? , entre hermanos no se repite el mismo nombre, pero sí puede suceder entre primos, de hecho, en nuestro ejemplo tenemos a dos primos que se llaman Juan y a dos primas que se llaman Marta.
En el eslabón superior de esta familia también se dará esta característica: al ser hermanos entre sí los padres, ninguno de ellos tendrá el mismo nombre, por lo tanto, si designamos como clave principal de nuestra tabla la pareja formada por el nombre propio de cada hijo y el nombre propio de su padre respectivo, estaremos seguros que en cada registro anotaremos los datos de individuos completamente diferentes, aunque tengan el mismo nombre, el mismo apellido primero y el mismo apellido segundo.
Se podrá repetir el nombre del padre, se podrá repetir el nombre del hijo, pero nunca se podrá repetir la pareja (nombre_padre, nombre_hijo) porque en el caso de que así fuese, estaríamos hablando del mismo individuo.
Para ser más gráficos podemos pensar en estos diez guarismos: 0, 1, 2, 3, 4, 5, 6, 7, 8 y 9. Su combinación por parejas nos da 100 valores completamente diferentes aunque se repita 19 veces cada uno de ellos : 00, 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 .................85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98 y 99.
Una clave primaria puede estar definida por un grupo de atributos, que si bien pueden repetirse en un mismo atributo, la combinaciones existente en cada línea es única.
5 - Claves Externas
Vamos a ver una entidad que el usuario corriente sólo ve en parte: El listado total de los préstamos de los libros
Sólo lo ve en parte porque cuando la biblioteca presta un libro en la Ficha de lectura sólo están anotados aquellos registros relativos a ese libro en particular, pero en realidad se lleva el control en una tabla general con todos los préstamos realizados. Sería algo así:
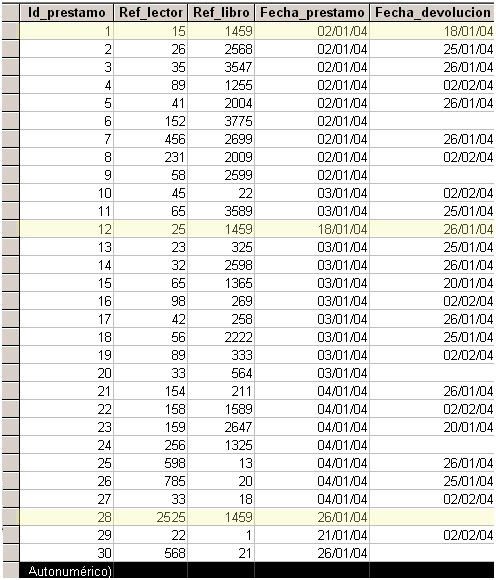
Cada ficha de lectura de un libro es una parte de la tabla general prestamos y está formada por los registros correspondientes al mismo libro, es decir, los registros que tienen el mismo valor para Ref_libro
Lo que nos aparece en la Ficha de lectura que acompaña al libro es nada más que una consulta a esta tabla. Es como si le hiciésemos una pregunta ¿ quién y cuándo ha leído el libro con referencia X?
Si miramos el estado del libro 1459, veremos que se ha prestado tres veces, podríamos averiguar las personas que lo han leído hasta ahora y también que en estos momentos lo tiene el lector 2525 porque no lo ha devuelto todavía.
Si quisiéramos ver más detalles de los lectores o del libro, buscaríamos en la tabla lectores y en la tabla libros los datos correspondientes a los Ref_lector y Ref_libro. de cada registro.
La tabla prestamos es básica en el control de la biblioteca, se pueden realizar consultas para saber qué libros están pendientes de devolución, qué lectores son los más activos, qué ha leído cada lector, qué libros son los más solicitados, podemos diseñar un control que nos avise si ha pasado un determinado tiempo y el libro está todavía sin devolver.....
Para realizar estas consultas es indispensable que al crear un registro en esta tabla préstamosexista ya el registro del lector en la tabla lectores y también el registro del libro en la tablalibros.
Aplicando la lógica se ve fácilmente que la biblioteca no podrá prestar un libro que no tiene y que no se lo prestará a una persona que no tenga dada de alta . Son dos condiciones que se tienen que cumplir a la vez: tener el libro y tener registrado al lector para que se pueda recoger una ocurrencia en la entidad préstamos
Tanto la Ref_libro como la Ref_lector son Claves externas de la tabla préstamos. También hemos definido aquí una Clave principal de manera que para cada registro haya un sólo valor único, no se repita ningún valor y el campo se auto incremente automáticamente, pero ésta vez no es visible al usuario. El identificador único de los registros de esta tabla se utiliza en operaciones internas y no es necesario que se muestre al usuario corriente.
Las claves externas adquieren un significado especial en la definición de las relaciones entre las tablas, determinan el tipo de relación existente entre ellas por lo que deben cumplir ciertas condiciones:
Lo que nos aparece en la Ficha de lectura que acompaña al libro es nada más que una consulta a esta tabla. Es como si le hiciésemos una pregunta ¿ quién y cuándo ha leído el libro con referencia X?
Si miramos el estado del libro 1459, veremos que se ha prestado tres veces, podríamos averiguar las personas que lo han leído hasta ahora y también que en estos momentos lo tiene el lector 2525 porque no lo ha devuelto todavía.
Si quisiéramos ver más detalles de los lectores o del libro, buscaríamos en la tabla lectores y en la tabla libros los datos correspondientes a los Ref_lector y Ref_libro. de cada registro.
La tabla prestamos es básica en el control de la biblioteca, se pueden realizar consultas para saber qué libros están pendientes de devolución, qué lectores son los más activos, qué ha leído cada lector, qué libros son los más solicitados, podemos diseñar un control que nos avise si ha pasado un determinado tiempo y el libro está todavía sin devolver.....
Para realizar estas consultas es indispensable que al crear un registro en esta tabla préstamosexista ya el registro del lector en la tabla lectores y también el registro del libro en la tablalibros.
Aplicando la lógica se ve fácilmente que la biblioteca no podrá prestar un libro que no tiene y que no se lo prestará a una persona que no tenga dada de alta . Son dos condiciones que se tienen que cumplir a la vez: tener el libro y tener registrado al lector para que se pueda recoger una ocurrencia en la entidad préstamos
Tanto la Ref_libro como la Ref_lector son Claves externas de la tabla préstamos. También hemos definido aquí una Clave principal de manera que para cada registro haya un sólo valor único, no se repita ningún valor y el campo se auto incremente automáticamente, pero ésta vez no es visible al usuario. El identificador único de los registros de esta tabla se utiliza en operaciones internas y no es necesario que se muestre al usuario corriente.
Las claves externas adquieren un significado especial en la definición de las relaciones entre las tablas, determinan el tipo de relación existente entre ellas por lo que deben cumplir ciertas condiciones:
En una tabla sólo se pueden recoger como clave externa aquellos valores que ya existan como clave principal en otra tabla.
Los nombres del campo de la clave principal y de la clave externa en un misma tabla, no deben ser idénticos.
Los nombres del campo de la clave principal y de la clave externa en un misma tabla, no deben ser idénticos.
Junto con las claves principales pueden utilizarse otras claves índice que sirven para clasificar rápidamente los campos y para encontrar los datos, aumentando la velocidad de las consultas por ese dato. Sólo se debe aplicar una clave índice cuando exista un problema real de velocidad, si una vez definido el nuevo índice no se obtiene el aumento de velocidad deseado hay que borrarlo para no perjudicar el rendimiento general de la base de datos.
Para crear una clave índice utilizamos los atributos KEY, INDEX y UNIQUE, éste último establece que el campo posea valores únicos y al intentar introducir un valor repetido dará una notificación de error.
6 – Conexiones
Vamos a ver cómo se pueden conectar o relacionar las entidades (tablas)Volvamos al paquetito de fichas de nuestra biblioteca particular:
Por la imagen y por la pura lógica deducimos que para cada libro tiene que existir un único listado de lectura:
Si un libro lo ha leído el lector 25, 150, y 1564 , es imposible que exista otro listado en el que aparezcan los lectores 25, 125, y 1564, o es cierto uno, o es cierto el otro, pero no pueden existir dos listados de lectura para el mismo libro, es decir, a cada libro le corresponderá un único listado (en este caso , ficha) de lectura a este tipo de relación entre entidades se le denomina de uno a uno
Otras relaciones de uno a uno serían: De un hijo hacía su madre biológica o la de un coche con su motor
Siguiendo con la pura lógica comprenderemos que en la biblioteca , un libro pueden haberlo leído varios lectores, por lo tanto, en la ficha de lectura están anotados más de un lector.
Una ficha de lectura estará relacionada con varios lectores, a esta relación se le denomina dede uno a varios
Otra relación de uno a varios sería : De una madre biológica hacia sus hijos. Pero ....
Entre dos entidades no pueden establecerse dos tipos diferentes de relaciones, por eso, es importante distinguir la diferencia entre los dos ejemplos adicionales que he incluido.
En el caso del coche con su motor puede estar más claro, sabemos que un coche sólo puede llevar un motor y a la inversa, un motor sólo puede ir en un coche. Si tuviésemos que gestionar la entidad coches y la entidad motores, podríamos estructurarlas de manera que se relacionasen por sus claves principales.
Cada id autonúmerico de la tabla coches lo podríamos relacionar con un id autonumérico de la tabla motores. La relación sería de uno a uno y verdadera en las dos direcciones:
para cada id_coches
Si un libro lo ha leído el lector 25, 150, y 1564 , es imposible que exista otro listado en el que aparezcan los lectores 25, 125, y 1564, o es cierto uno, o es cierto el otro, pero no pueden existir dos listados de lectura para el mismo libro, es decir, a cada libro le corresponderá un único listado (en este caso , ficha) de lectura a este tipo de relación entre entidades se le denomina de uno a uno
Otras relaciones de uno a uno serían: De un hijo hacía su madre biológica o la de un coche con su motor
Siguiendo con la pura lógica comprenderemos que en la biblioteca , un libro pueden haberlo leído varios lectores, por lo tanto, en la ficha de lectura están anotados más de un lector.
Una ficha de lectura estará relacionada con varios lectores, a esta relación se le denomina dede uno a varios
Otra relación de uno a varios sería : De una madre biológica hacia sus hijos. Pero ....
Entre dos entidades no pueden establecerse dos tipos diferentes de relaciones, por eso, es importante distinguir la diferencia entre los dos ejemplos adicionales que he incluido.
En el caso del coche con su motor puede estar más claro, sabemos que un coche sólo puede llevar un motor y a la inversa, un motor sólo puede ir en un coche. Si tuviésemos que gestionar la entidad coches y la entidad motores, podríamos estructurarlas de manera que se relacionasen por sus claves principales.
Cada id autonúmerico de la tabla coches lo podríamos relacionar con un id autonumérico de la tabla motores. La relación sería de uno a uno y verdadera en las dos direcciones:
para cada id_coches
> habría un id_motores
para cada id_motores
para cada id_motores
En el caso de la madre con su hijo, es diferente.
Si bien es cierto que un hijo sólo puede tener una madre biológica, también es cierto que una madre biológica puede tener varios hijos.
Si tuviésemos que gestionar la entidad hijos y la entidad madres y les diésemos esta estructura y atributos.

Sería imposible trazar una relación verdadera y única desde la entidad madres hacia la entidad hijos por medio del id de ambas tablas, id referido a su clave principal ¿por qué?
Porque en el momento que tuviésemos que ingresar un nuevo registro de un nuevo hijo para la misma madre, la relación se establecería así para el primer hijo ( id de ejemplo):
al hijo A de id 20
Porque en el momento que tuviésemos que ingresar un nuevo registro de un nuevo hijo para la misma madre, la relación se establecería así para el primer hijo ( id de ejemplo):
al hijo A de id 20
--> le correspondería la madre de id 20 )
Pero ¿cómo podríamos relacionar al segundo?
madre (id 20) |
Pero ¿cómo podríamos relacionar al segundo?
madre (id 20) |
--> hijoA (id 20)
|
|
Hemos dicho que la clave principal tiene que ser única, por lo tanto no podemos volver a repetir el id 20 en la tabla hijos
Para poder relacionarlas tenemos que crear un nuevo campo en la tabla hijos, algo que nos diga exactamente a que madre pertenece y que además se pueda repetir el valor dentro de ese campo para varios registros, tendríamos que establecer una clave externa.

Tendríamos algo así:
madre (id 20) |
madre (id 20) |
--> hijoA (id-madre 20) (id 20 )
madre (id 20) |
madre (id 20) |
Relacionaremos la clave principal de la tabla madres con el campo de la tabla hijos que nos diga "el nombre de la madre (id-madre)"
La clave principal de la tabla hijos, la que nos determina "el nombre del registro de cada hijo" permanecería único y sin repetirse.
Relación de varios a varios
Las entidades de nuestra biblioteca mostradas en esquema estarían así:

Entre la tabla lectores y la tabla libros hay una relación de varios a varios.
Voy a dejaros que analiceis vosotros esta relación como ejercicio, pero antes leed el análisis que hago de otra posible relación de varios a varios que se puede dar en nuestra biblioteca.
Imaginemos cómo están archivados los libros en una biblioteca real. Cada lote de libros están clasificados por tipo, en una sección: narrativa, poesía, historia, libro técnico ....
Pero además cada libro estará escrito en un idioma diferente : francés, inglés, ...
Veremos que hay libros en francés de bricolaje e informática.
Voy a dejaros que analiceis vosotros esta relación como ejercicio, pero antes leed el análisis que hago de otra posible relación de varios a varios que se puede dar en nuestra biblioteca.
Imaginemos cómo están archivados los libros en una biblioteca real. Cada lote de libros están clasificados por tipo, en una sección: narrativa, poesía, historia, libro técnico ....
Pero además cada libro estará escrito en un idioma diferente : francés, inglés, ...
Veremos que hay libros en francés de bricolaje e informática.

Hay libros en inglés de novela, historia, ensayo e informática.

Hay libros en alemán de poesía y ensayo.

Hay libros en italiano de poesía y ensayo.

Si considerásemos hacer la clasificación de las secciones por idiomas en lugar de por tipo de libro, la relación sería también válida y quedaría así:
Hay libros de novela en francés e inglés.
Hay libros de novela en francés e inglés.

Hay libros de poesía en alemán e italiano.

Hay libros de historia en inglés.

Hay libros de bricolaje en francés.

Hay libros de botánica en alemán e italiano.

Hay libros de ensayo en inglés e italiano.

Hay libros de informática en francés e inglés.

Si representamos estas relaciones en una sola figura nos quedaría esto:

A esta relación se le denomina de varios a varios
Podemos encontrar relaciones de este tipo en muchos casos de la vida diaria, son relaciones de varios a varios,:
En el restaurante: En el menú hay varios platos, al restaurante van varios clientes. Cada cliente pedirá varios platos y un mismo plato lo pedirán varios clientes .
Varios platos para varios clientes
En la escuela: En un curso hay varias asignaturas optativas, en ese curso hay varios alumnos. Cada alumno estudiará varias asignaturas optativas y cada asignatura optativa será elegida por varios alumnos.
Varias asignaturas para varios alumnos
En el campeonato mundial de motociclismo: Hay varias competiciones válidas para puntuar en él, hay varios corredores inscritos en todas. Varios corredores puntuarán en una competición que se sumará al resto de pruebas para ganar el campeonato, una competición será ganada por varios corredores ( los tres clasificados : primero, segundo y tercero en cada prueba)
Varias pruebas para varios corredores.
Podemos encontrar relaciones de este tipo en muchos casos de la vida diaria, son relaciones de varios a varios,:
En el restaurante: En el menú hay varios platos, al restaurante van varios clientes. Cada cliente pedirá varios platos y un mismo plato lo pedirán varios clientes .
Varios platos para varios clientes
En la escuela: En un curso hay varias asignaturas optativas, en ese curso hay varios alumnos. Cada alumno estudiará varias asignaturas optativas y cada asignatura optativa será elegida por varios alumnos.
Varias asignaturas para varios alumnos
En el campeonato mundial de motociclismo: Hay varias competiciones válidas para puntuar en él, hay varios corredores inscritos en todas. Varios corredores puntuarán en una competición que se sumará al resto de pruebas para ganar el campeonato, una competición será ganada por varios corredores ( los tres clasificados : primero, segundo y tercero en cada prueba)
Varias pruebas para varios corredores.
Por lo general este tipo de relaciones se dan entre dos tablas que tienen "interpuesta entre ambas" otra tabla que es en la que recaen la dos partes "varios".
En el ejemplo de nuestra biblioteca la relación de varios a varios entre los libros y los lectoresse estable por medio de la tabla préstamos.
un libro lo leen varios lectores |
> prestamos <
-| un lector lee varios libros
La tabla prestamos irá presentando en cada uno de sus registros las combinaciones de las claves principales entre la tabla lectores y la tabla libros.
7 - Integridad Referencial
A partir de la versión 4.0 con MySql se puede verificar la integridad referencial . Antes, para poder controlar este factor era necesario utilizar el comando SELECT .... LEFT JOIN, pero en la version 4.0. se ha agregado a la lista de tipos de tablas soportadas en una instalación típica el tipo InnDb , en dónde podemos definir reglas o restricciones que garanticen la integridad referencial de los registros.
Las claves proporcionan una manera rápida y eficiente de buscar datos en una tabla, además de que permiten preservar la integridad de los datos.
Ya hemos visto que la clave primaria debe ser única y no nula, de manera que garantice que una fila de una tabla pueda estar siempre referenciada a través de su clave primaria. Es un campo, o una combinación de campos, que identifican de manera única un registro de una tabla.
Podemos decir de manera simple que integridad referencial significa que cuando un registro en una tabla haga referencia a un registro en otra tabla, el registro correspondiente debe existir.
Como vimos en un capítulo anterior para ingresar un registro en la tabla préstamos era imprescindible tener con anterioridad el registro correspondiente del libro en la tabla libros y el registro correspondiente del lector en la tabla lectores
Básicamente la integridad referencial es esa necesidad: la exigencia de que cuándo un registro de una tabla haga referencia a un registro de otra tabla, ese registro debe existir ya.
No existiría integridad referencial en el caso que pudíesemos tener un registro en la tabla prestamos que nos indicase que se ha prestado un libro inexistente en la biblioteca. Cuando en una base de datos se da una situación semejante, se dice que tiene una integridad referencial pobre. Generalmente esto va ligado a un mal diseño, y puede generar otro tipo de problemas en la base de datos .
Las relaciones de claves externas se describen como relaciones padre/hijo (en nuestro ejemplo, lector y libro son tablas padre y prestamos es la tabla hija), y se dice que un registro es huérfano cuando su padre ya no existe
En el pasado, MySQL no se esforzaba en evitar este tipo de situaciones, y la responsabilidad pasaba a la aplicación. Para muchos desarrolladores, esta no era una situación del todo grata, y por lo tanto no se consideraba a MySQL para ser usado en sistemas "serios". Por supuesto, una de las cosas más solicitadas en las anteriores versiones de MySQL fué que se tuviera soporte para claves externas, para que MySQL mantuviese la integridad referencial de los datos.
Para que un campo sea una clave externa, necesita estar definido como tal en el momento de crear una tabla. Se pueden definir claves externas en cualquier tipo de tabla de MySQL, pero únicamente tienen sentido cuando se usan tablas del tipo InnoDB.
Para trabajar con claves externas necesitamos que las dos tablas que se van a relacionar sean de tipo InnoDB.
InnoDB no crea de manera automática índices en las claves así que se deben crear de manera explícita. Los índices son necesarios para que la verificación de las claves foráneas sea más rápida.
La integridad referencial se puede comprometer básicamente en tres situaciones: cuando se está insertando un nuevo registro, cuando se está eliminando un registro, y cuando se está actualizando un registro.
En la práctica II crearemos nuestra propia base de datos con tablas de este tipo y veremos qué pasa cuándo trabajamos con ellas.
8 - Practica I
En estos apuntes no entraré a explicar como se instala MySql o como se configura el archivo my.cnf. El motivo no es que no lo crea interesante, interesante lo es, pero presupongo que los lectores de estos apuntes no son programadores sino personas que se han acercado a MySql movidos por la necesidad de entender el funcionamiento de los foros phpBB que se han instalado. Imagino que tenéis un proveedor que os facilita la interfaz gráfica phpMyAdmin y que cuándo habéis accedido a MySql habéis pensado ¡madre mía! ¿Y ahora qué? .
Doy por supuesto que vuestro proveedor, como profesional que es, se ha preocupado de establecer las medidas de seguridad adecuadas y que ha establecido los permisos oportunos para que cada usuario acceda a su "porción" del administrador, a su zona, de la base de datos.
Lo que nosotros vemos y dónde nosotros actuamos, es una parte del administrador, es nuestra casa . Un apartamento en un gran edificio formado por muchos apartamentos. Lo primero que vamos a hacer es un recorrido "turístico" por el administrador de MySql, nos conectaremos con nuestro usuario y contraseña para inspeccionar el "apartamentito":
nos muestra a la izquierda todas las tablas de que consta el foro y debajo tenemos un enlace a una ventana un enlace a una ventana aquí podremos hacer consultas con el lenguaje SQL cuando sepamos más. A la derecha tenemos un casillero con un menú desplegable para que podamos elegir el idioma en el que queremos trabajar.
nos muestra a la izquierda todas las tablas de que consta el foro y debajo tenemos un enlace a una ventana un enlace a una ventana aquí podremos hacer consultas con el lenguaje SQL cuando sepamos más. A la derecha tenemos un casillero con un menú desplegable para que podamos elegir el idioma en el que queremos trabajar.
Haciendo clic sobre Bases de Datos aparece una ventana con todas las bases de datos a las que tenemos acceso, desde aquí podemos acceder a la estructura de la base
En realidad vosotros no lo veréis así, yo he puesto una imagen combinada en castellano y en inglés.
En esta página se encuentran listadas las 29 tablas que conforman la base de datos de los foros. A la derecha de cada una podemos elegir qué acción realizar en ella:
- Podemos examinar todos los registros que tenemos uno por uno.
- Podemos seleccionar una tabla para realizar en ella una consulta.
- Podemos insertar un nuevo dato.
- Podemos ver las propiedades de una tabla
- Podemos eliminar una tabla.
Las últimas dos columnas nos indican el tipo de tabla MyISAM y su tamaño
Tablas
Mi base de datos la instalé con el prefijo foro_. Ya se ha comentado en este sitio lo interesante que es instalar la base de datos con un prefijo. Normalmente los proveedores permiten que dispongamos de una determinada capacidad en la base de datos, pero sólo te dejan instalar una. Con este sistema podemos instalar varias "bases de datos" juntas, cada una funcionando con su prefijo.
Pensemos por un momento qué tipo de datos vamos a manejar en el foro.
Por una parte gestionaremos los usuariosy todos los datos referidos claramente a ellos ( datos personales, grupo al que pertenecen)
Por una parte gestionaremos los usuariosy todos los datos referidos claramente a ellos ( datos personales, grupo al que pertenecen)
Por otra parte gestionaremos los mensajes(post) y todo lo relacionado claramente con ellos ( temas, foros, envío de mensajes,.... )
Aparte de los mensajes en los foros gestionaremos los mensajes personales con todo lo relacionado claramente con ellos ( bandeja de salida, entrada .....)
Y además aquellas entidades, que se irán creando y modificando con características tanto de los usuarios como de los mensajes que esos usuarios vayan emitiendo.(por ejemplo los rangos)
Por último, señalar que existirán unas tablas específicas para los datos de configuración del foro.
Si desde la relación total de tablas que conforman la base cliqueamos en las"propiedades" de una de ellas veremos como está estructurada, sus campos , índices etc... abajo está la opción "vista de impresión" ....
Os propongo que imprimáis las tablas y hagáis cinco grupos con ellas: tablas de usuarios, tablas de mensajes que parecerán en el foro, tablas de los mensajes personales, tablas "mixtas", tablas de configuración. Marcar con un color la clave principal de cada una de ellas y con otro color las claves externas. Las tablas que no veáis claramente a dónde pertenecen ponedlas en un grupo aparte.
En un montoncito tendréis aquellas con las características exclusivas de los usuarios, en el otro las que poseen las características exclusivas de los mensajes y en un tercero las tablas que hemos querido denominar "mixtas", para entendernos por el momento.
Mirad una por una cómo se relacionan con las demás. Fijaros que habrá tablas que sólo tengan una clave principal pero habrá otras que tengan varias claves externas, eso os dará una pista del tipo de relación entre ellas.
9 - Modelos de Gestores de Bases de Datos
El esquema lógico de la información en una base de datos se compone de un conjunto de entidades que pueden compartir información entre ellas mediante unas conexiones. En nuestro ejemplo de referencia serían la tabla libros que equivalen a las fichas con los datos de los libros de una biblioteca, la tabla lectores que equivale a las fichas de lectores de esa biblioteca y las relaciones entre ambas tablas.
Dependiendo de cómo estén definidas las relaciones y las entidades estaremos ante un gestor de base de datos relacional, jerárquico o en grafo
Gestor relacional: Una base de datos relacional consiste en una colección de tablas a cada una de las cuales se le asigna un nombre único y una fila de una tabla representa una relación entre un conjunto de valores, un registro.
Dependiendo de cómo estén definidas las relaciones y las entidades estaremos ante un gestor de base de datos relacional, jerárquico o en grafo
Gestor relacional: Una base de datos relacional consiste en una colección de tablas a cada una de las cuales se le asigna un nombre único y una fila de una tabla representa una relación entre un conjunto de valores, un registro.
Tablas:
Tabla libros / Tabla lectores

Un registro en la tabla libro : Los Miserable / Victor Hugo / Ed.Planeta / 1956 / castellano / novela.

Un registro de la tabla lectores Pedro / Primero / Casa / Los pinos, 27 / 123456789/ 5698741
Operaciones que se pueden realizar
Inserción: Para insertar un nuevo libro o un nuevo lector lo único que hay que hacer es añadir al final de la tabla de libros o lectores una nueva ocurrencia, y cuando se preste un libro a un lector se registra en una tabla general prestamos . No se puede añadir un registro en la tabla préstamos si no existe el registro de la tabla lector y de la tabla libro.
Apliquemos otra vez la pura lógica: si no tengo un libro no puedo prestarlo y si una persona no está registrada en la biblioteca no le prestarán ningún libro.
Borrado : Se puede borrar sin ningún problema el registro de lectura. Para borrar un lector o un libro hay que actualizar la información del préstamo, eliminando otras apariciones de ese libro o ese lector.
En estos apuntes vamos a tratar de entender como funciona MySql y este gestor de bases de datos es un gestor de tipo relacional, pero existen otros tipos de gestores que definen las entidades y estructuran las conexiones de una manera diferente.
Supongo que los que estáis leyendo esto os iniciáis en el tema de las bases de datos, por lo tanto no me extenderé con los otros tipos de gestores, creo que es mejor comprender como funciona de momento éste, si en un futuro hablamos de Oracle , SQL Server, PostgreSql o Interbase, partiremos de este capítulo para explicar con más detenimiento como trabajan los gestores jerárquicos o en grafo. Ahora sólo dos pinceladas.
Gestor jerárquico
Su estructura básica es el árbol. Va a tener un nodo padre y una serie de nodos hijos, la conexión se hace eligiendo quien va a ser el padre y quien va a ser el hijo.
El árbol se puede implementar mediante:
a) Registros variables: Son registros que van creciendo según se aumente el archivo.
b) Cadenas de punteros.
b) Cadenas de punteros.
Operaciones que se pueden realizar:
Inserción: Insertar un padre se hace sin problemas. No se puede insertar un hijo sin estar asociado a un padre. La inserción va bien siempre que no se quiera insertar un hijo que no tenga padre.
Borrado: Si se borra un padre se borran todos sus descendientes.
Modificación: Si se modifica un hijo hay que modificarlo en todos los árboles en que se encuentre.
El problema de esta implementación es que los árboles solo permiten representar una estructura de uno a muchos, por tanto no es eficiente cuando se tiene que implementar una estructura de muchos a muchos.
Gestor en grafo
Se implementa mediante cadenas de punteros. Contiene dos tipos de conjuntos:
1. Conjunto de registros: libros , lectores.
2. Conjunto de ligas: préstamos (Cantidad).
2. Conjunto de ligas: préstamos (Cantidad).
Una ocurrencia de un tipo de registro específico puede tener cualquier número de superiores inmediatos. Se pueden representar relaciones de muchos a muchos.
Su desventaja más importante es su gran complejidad en la realización de los algoritmos y la cantidad de memoria que hay que reservar para los punteros.
Objetivos de los Sistemas de Gestión de Bases de Datos
Las funciones de un SGBD son:
Debe permitir la perfecta definición de todos los datos. Es decir debe permitir incorporar a las estructuras todos aquellos objetos necesarios para completarlas y debe permitir incluir todos los atributos necesarios para definir a los objetos.
Debe permitir la manipulación de los datos: operaciones de intercambio de datos entre las tablas que pueden ser de consulta o de puesta al día (inserción, modificación supresión)
Debe establecer controles de seguridad para esos datos garantizando que sólo los usuarios autorizados puedan efectuar operaciones correctas bien sobre toda la base de datos o sobre algunas tablas.
Debe permitir los accesos concurrentes. El principal objetivo de la implantación de una base de datos es poner a disposición de un gran número de usuarios un conjunto integrado de datos y que estos datos puedan ser manipulados por los diferentes usuarios . El SGBD debe garantizar que esos datos seguirán siendo coherentes después de las diversas manipulaciones.
Una mala concepción a la hora de diseñar una base de datos puede dar origen a:
La redundancia de datos . Existiría redundancia de datos por ejemplo, si no creásemos una tabla de lectores y nos viésemos obligados a repetir en la tabla libros los datos del lector cada vez que prestamos un libro
Incoherencia en los datos . Si después de manipular los datos las consultas nos devolviesen definiciones erróneas. Por ejemplo, si no se estableciese como clave externa de la tabla préstamos la clave primaria del libro, en cuanto empezásemos a dejar libros a los lectores sobrevendría un caos, pues sería imposible determinar quién tiene qué libro
Pérdida de datos . Por ejemplo, si la supresión de una línea en la tabla libros (dar de baja un libro) supusiese también la eliminación de todos los registros de aquellos lectores que han leído el libro. A este comportamiento se le denomina "comportamiento anormal de las tablas"
Estado de la tabla . Decimos que una tabla se encuentra en estado de primera forma, si todas columnas de la tabla contienen valores atómicos y decimos que un valor es atómico cuándo es indivisible. Por ejemplo, si en la tabla libros dedicásemos una columna para anotar el título del libro y del autor, o en la tabla lectores dedicásemos una columna para anotar la dirección completa del usuario( calle, número y piso) las tablas no estarían en primera forma.
Lenguaje de los Sistemas de Gestión de Bases de Datos
Para "hablar" con un administrador de bases de datos utilizamos el lenguaje SQL. En la red encontraréis excelentes tutoriales que explican ampliamente sus características, yo os recomiendo este Curso de Sql
Como la mejor manera de aprender es practicar, os propongo que sigáis los pasos del tutorial y que practiquéis en vuestro administrador de base de datos de los foros. Veréis cuanta información aprederéis a sacar de ella.
Fuentes: